From Medium to My Own Blog: How Hermes Agent Built, Migrated, and Translated My Writing Archive
A four-hour experiment in using Hermes to build a blog, migrate 25 Medium articles, translate them into Chinese, and test the limits of AI agent workflows.
The Feeling of a Project That Should Have Stayed in My Notes App
I had been thinking about moving my Medium articles to my own blog for a while.
Not because I wanted to abandon Medium. Medium is still a useful place to publish. It gives writing a surface, a network, a chance to travel beyond your own circle.
But after writing more seriously about AI, software engineering, and storytelling, I started feeling the need for a home base. Medium felt like a rented apartment. Useful, convenient, nicely furnished — but still not quite mine.
I wanted a place with my own structure, my own design, my own archive, and eventually, both English and Chinese versions of my work.
The math was simple but discouraging: roughly 25 articles, each needing scraping, formatting, page-building, tagging, and — because I wanted bilingual publishing — Chinese translation. By hand, that’s more than a weekend. In practice, it’s one of those tasks that sits in your notes app under “personal website migration” until you change email providers.
I have heard a lot about Hermes agent recently. So I decided to give it a try.
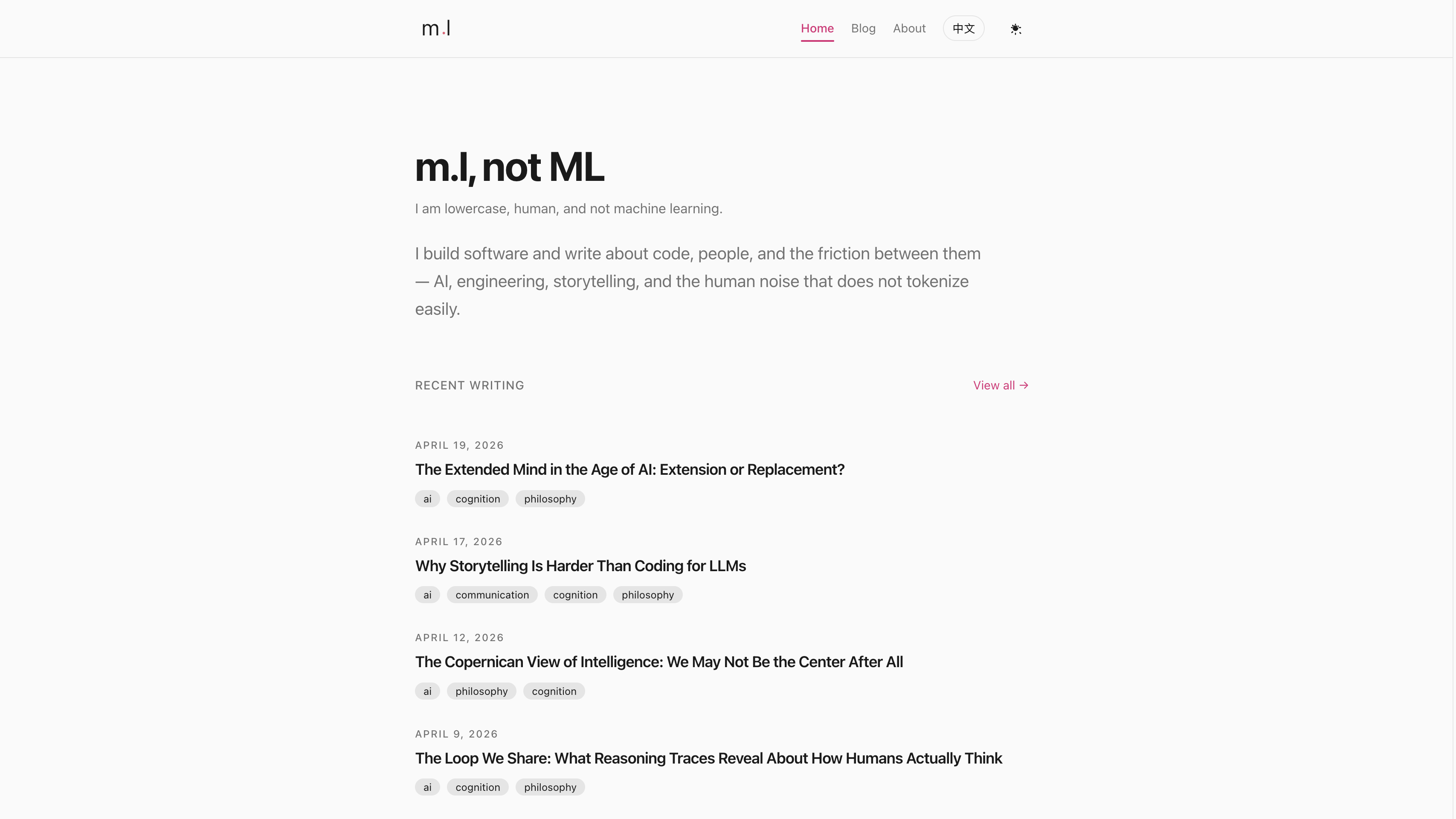
What happened was: in less than four hours, I had a working blog site with my articles migrated, translated, tags and categories set up, and an About Me section that was somehow better than the one I would have written myself.
That sounds like the kind of sentence people write when they want to make AI sound magical.
But the more interesting story is not that it worked. The more interesting story is where it almost worked.
The Migration: Scraping Was Useful, But Not Perfect
The first thing I asked the agent to do was scrape my Medium archive.
This turned out to be harder than either of us expected. Medium is not exactly designed to make bulk extraction simple. There are previews, page structures, limitations, and different ways content can be exposed depending on the page.
The first attempts did not capture the full article content correctly. The agent had to adjust. Try one way. Fail partially. Inspect. Try another way. Improve.
After several rounds of trial-and-feedback, it successfully pulled down 20 out of 25 articles and formatted them almost perfectly. Five were unreachable — paywalled, restricted, or structured in a way the scraping approach couldn’t handle in bulk.
That 80% in one go was impressive, but what mattered was that I had to check. I had to count the articles. I had to notice the gap. The agent could scrape, but it couldn’t tell me what it missed.
So I went back and manually pasted each of the five missing article links into the agent. Individual URLs are less guarded than bulk archive pages. This time it worked. By the end, all 25 were on disk.
That result was both impressive and grounding.
Impressive, because manually copying and organizing 25 long articles would have been tedious. I probably would have postponed the whole project again.
Grounding, because the agent did not magically bypass every constraint. It still had to work within the limits of the platform. It still missed things. It still needed validation.
Scraping is not intelligence. Scraping is negotiation. The agent was negotiating with Medium’s structure, and it got far enough to be useful, but not far enough to be trusted blindly.
The Site Design: Less Is Not Nothing
I told the agent I wanted a minimal blog. Not a loud portfolio. Not a startup landing page. A quiet place for writing, with a pink accent color, and the article as the main character.
The agent designed the site, set up the structure, created the routes, organized the content. It chose a clean theme with both light and dark modes, generous whitespace, pink accents, a layout that puts the text front and center.
This part felt surprisingly smooth because the requirements were clear. A blog is a well-understood pattern. There are article lists, article detail pages, navigation, metadata, and maybe language variants. The agent did not need to invent a new product category. It needed to implement a familiar pattern with my preferences.
That is exactly where agents are useful.
When the goal is structured enough, and the taste direction is clear enough, they can move very fast.
The site did not need to be perfect on the first pass. It needed to exist. That alone changes the energy of a project.
Translation: Fast, But “Translated” Did Not Mean “Done”
I asked the agent to translate all 25 articles into Chinese.
The first pass came back looking complete, until I actually read it.
Some sentences were translated cleanly, but others felt rigid and unnatural. There were English words scattered throughout. A phrase would be beautifully translated. Then the next paragraph would have an English term sitting there like a pebble in rice. “exhilarating.” “prosper.” Small words that broke the immersion completely.
It looked done from a distance. It was not done up close.
I asked the agent to do a second round, specifically targeting these leftover English fragments. The second pass fixed most of them, but not all. I caught a few during my own review.
Translation is a perfect example of the gap between “generated” and “publishable.” A technical sentence can survive a rough translation. A reflective sentence cannot. And when your writing is personal, when the tone carries half the meaning, the distance between generated and publishable is much wider than it looks at first glance.
The first draft had the basic meaning. The second pass made it more complete. But even then, I would not treat translation as a fully automated step for writing I care about.
The About Me That Made Me Pause
The most surprising moment of the whole migration had nothing to do with scraping or design.
It was the About Me section.
The agent scraped my Medium profile page. But it did not stop there. It also, apparently read through my articles. And it synthesized details I hadn’t explicitly told it about myself.
My background in communications alongside software engineering. The through-line of my writing: AI, cognition, storytelling, how technology changes the way people think. Details I never put in any bio.
The agent wrote a better About Me than I would have written.
That felt strange. Not creepy, exactly. More like being summarized by someone who had read your work more carefully than you expected.
Writing a bio is weirdly difficult. Most of us either undersell ourselves, oversell ourselves, or flatten ourselves into job titles. We write what we think we are allowed to say, not necessarily what our work has been saying all along.
The agent didn’t have that hesitation. It looked across the writing and found the through-line. It saw the shape before I named it.
This might be one of the underrated uses of AI in creative work: not generating something from nothing, but reflecting back the pattern already present in your own body of work.
It did not invent me. It compressed the evidence of me.
The First Round Used Kimi K2.6
For the first round of this migration, I used Kimi K2.6.
I do not want to turn this into a model leaderboard, because that was not the point of the experiment. I was less interested in whether one model “wins” and more interested in whether the model could stay useful across a messy, multi-step workflow.
This was not a single prompt task. It involved scraping, debugging, file organization, site design, translation, cleanup, and iteration. That is the kind of workflow where model capability matters, but so does tool use, persistence, context handling, and the ability to recover from partial failure.
Kimi K2.6 helped push the project from idea to working site quickly. But the more important lesson was not about one model. It was about the shape of the collaboration.
I was not asking the model to give me advice. I was asking it to operate.
And that is a very different test.
Multi-Agent From a YouTube Link
After the migration, I started experimenting with a multi-agent setup.
I had heard about the concept: different agents with different roles, running in parallel, sharing memory, handing off work. It sounded powerful in theory.
I learned the multi-agent setup from a YouTube video about shared memory and logs. The creator made a suggestion that sounded almost too simple: paste the video link into the agent and ask it to build the system.
So I tried it. I copied the YouTube link, pasted it into Hermes, and typed “create the multi-agent setup for me”. To my surprise, it worked. The agent turned the idea from the video into an actual working structure.
That sentence still feels absurd. But that is what happened.
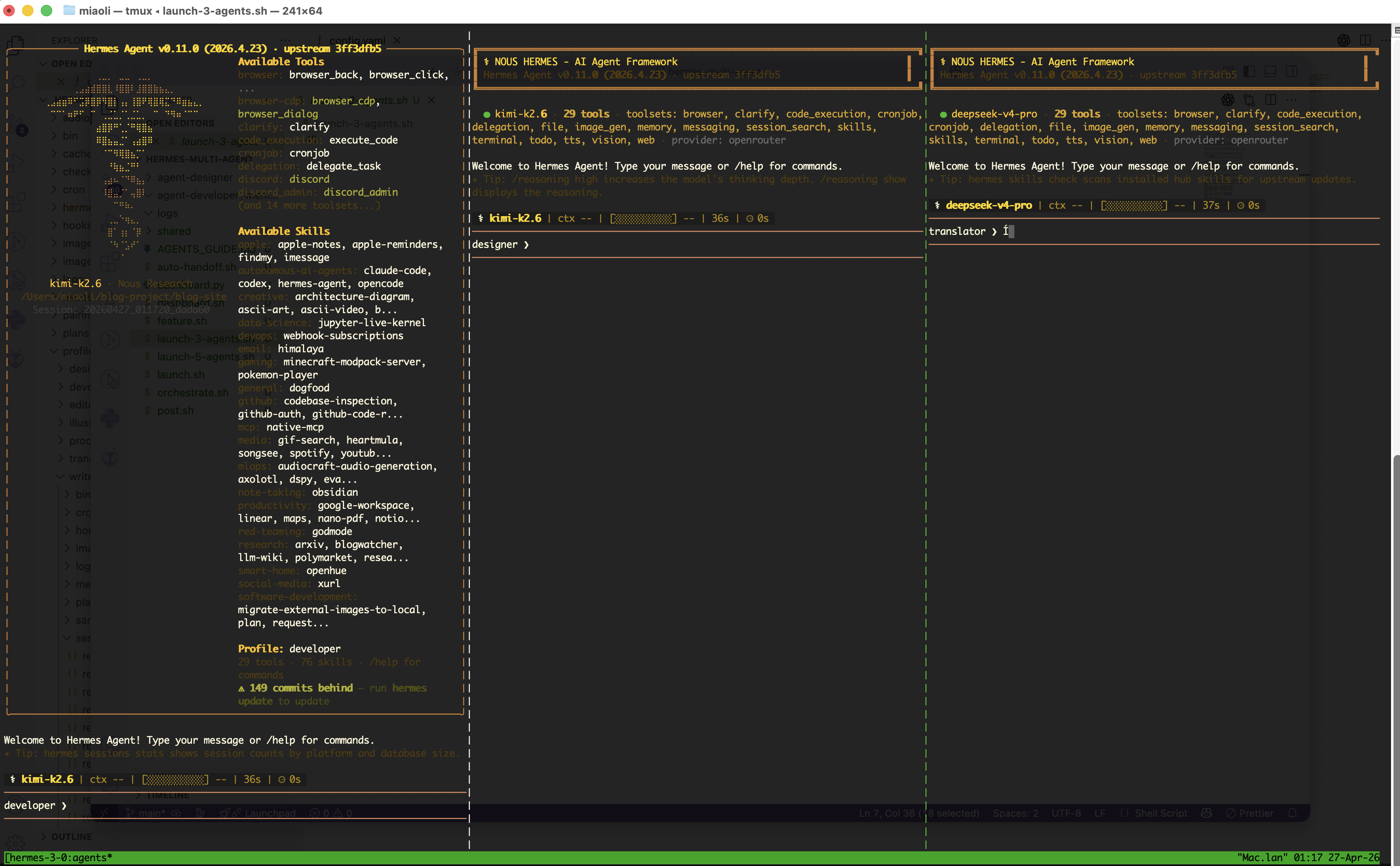
The agent created the whole setup: a shared workspace directory, daily logs for each agent role, a handoff protocol using markdown files, and tmux launcher scripts that open multiple agents side by side.
I started with three agents: Writer, Designer, and Translator. Each with its own persona. Each assigned a different model. Running in parallel, side by side in a tmux session. The Writer drafts. The Designer thinks about presentation. The Translator converts language.
The shared workspace was the key insight: a filesystem as a mailbox. One agent writes a file. Another agent reads it. No complex infrastructure. Just conventions and markdown files.
The End-to-End Article Pipeline
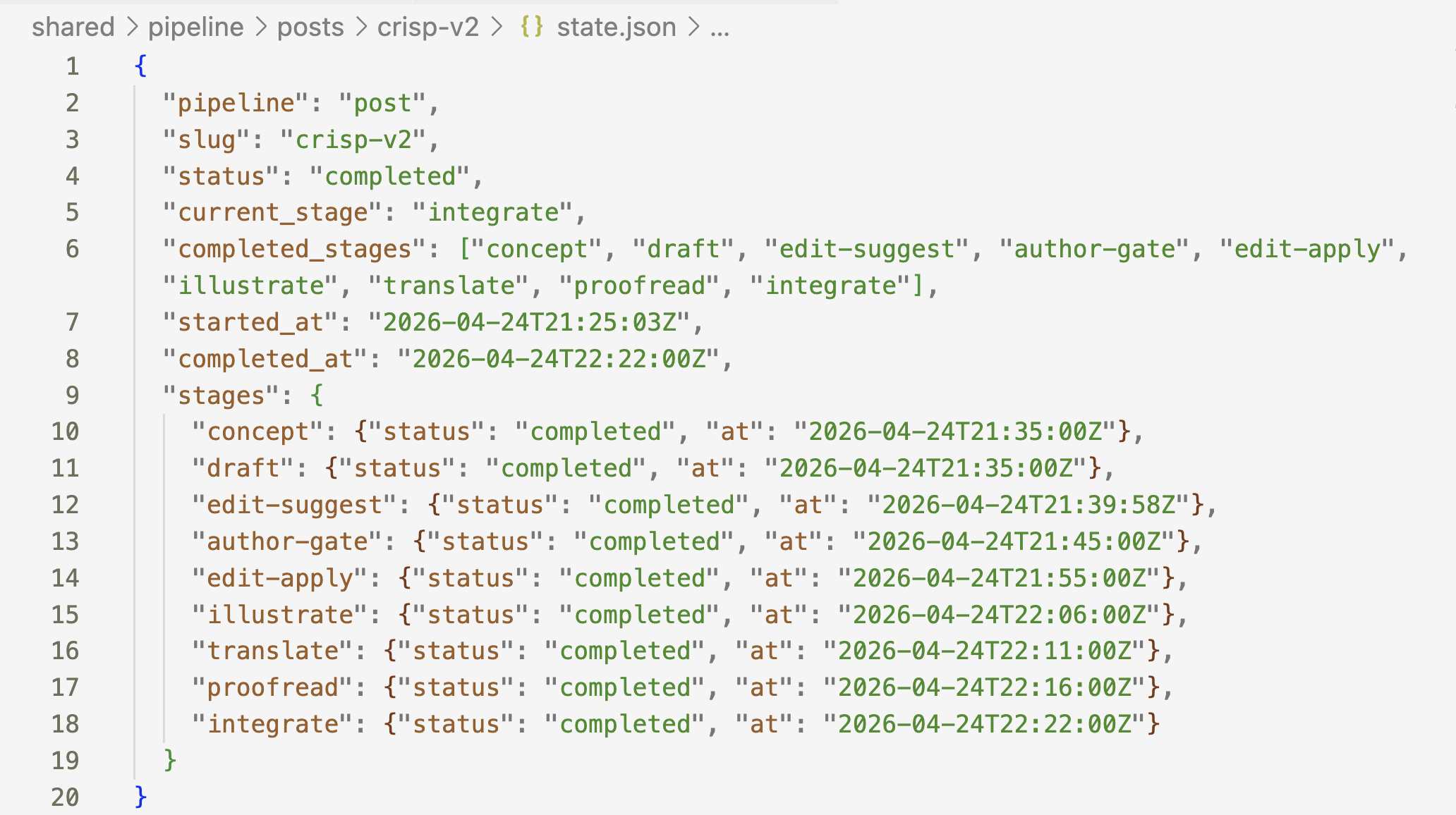
I pushed further and built an end-to-end pipeline using an orchestrator script. The flow looked like this:
concept → draft → edit-suggest → author-gate → edit-apply → illustrate → translate → proofread → integrate
In theory, it was beautiful. It looked like a small editorial production team running inside your machine.
Each stage is handled by a different agent profile, with a different model assigned based on the task:
| Agent | Stage | Model - default / backup |
|---|---|---|
| Writer | Concept & Draft | deepseek-v4-pro / kimi-k2.6 |
| Editor | Edit (suggest + apply) | gpt-5.5 / kimi-k2.6 |
| Illustrator | Image generation | gpt-5.4-image-2 |
| Translator | Chinese translation | deepseek-v4-pro / kimi-k2.6 |
| Proofreader | Final quality review | gpt-4o-mini / kimi-k2.6 |
| Developer | Publish & integrate | kimi-k2.6 |
The pipeline was designed around auto-handoff. One stage produces output, the next stage picks it up, and the system moves forward. Illustrate and Translate run in parallel — images and translation happen simultaneously. The author-gate pauses the pipeline for human review, then edit-apply picks up the approved changes and the pipeline continues.
I ran it through a full cycle on one article. The whole flow took about 50 minutes. I did not provide human feedback at the author-gate stage. I wanted to see what the system could do on its own.
The Honest Assessment: 50 Minutes vs. What I Get With Iteration
The result was far from ideal compared to what I usually get when I iterate with one agent over multiple rounds.
The writing was structurally sound but lacked the sharpness I get when I work through multiple rounds with a single agent. The translation had the same English-fragment problem as the migration pass. The proofreading caught some issues but missed others.
There’s a specific failure mode here that I want to name: once a workflow becomes smooth, it can move weak work forward very efficiently.
A bad draft becomes a bad translated draft. A vague concept becomes a polished but still vague article. A weak sentence gets proofread instead of rewritten. A generic idea gets integrated instead of challenged.
In a human editorial process, someone would stop and say: “Wait, what are we really trying to say?”
The automated pipeline did not do enough of that.
It moved. It did not pause. And good writing often depends on the pause.
The bottlenecks were in the stages that require taste: writing, editing, and translating. These are not mechanical tasks. Writing is not prompt-following. Editing is not find-and-replace. Translation is not word-swapping. All of them require an understanding of what the text is trying to be, not just what it currently is.
The multi-agent flow created a complete artifact. But complete is not the same as good.
I still think multi-agent workflows have real potential. But the experiment confirmed something I suspected: one agent with human iteration still beats many agents without human judgment.
The bottleneck is not throughput. It is taste. And taste cannot be pipeline-ized.
Thoughts on the Human Role
After all this, I don’t think the right question is “Can AI agents do the work?”
The better question is: Which part of the work is labor, and which part is judgment?
The agent compressed the labor brilliantly. It scraped. It created files. It built pages. It translated drafts. It generated structure. It created the multi-agent system. It ran the pipeline.
But I still had to judge the result. I had to notice the 5 missing articles. I had to catch the incomplete translations. I had to decide whether the design felt right. I had to recognize that the About Me was surprisingly good. I had to compare the pipeline output against my own quality bar.
That is the human role I keep coming back to. Not doing every manual step. Not pretending AI cannot help. But also not giving up control.
The useful role is becoming more like an editor, architect, and taste-keeper at the same time. You define the outcome. You create the constraints. You review the work. You decide what gets published.
The agent can do a lot. But “a lot” is not the same as “the final call.”
Where the Real Improvement Is Needed
If I were to build a better version of this pipeline tomorrow, I wouldn’t add more agents. I would add better gates. The workflow needs more judgment points, not more throughput.
The author-gate should not be optional. No human feedback, no next stage. Otherwise, the system just becomes an assembly line for first drafts that look complete but aren’t.
The editor needs to be more opinionated. Not just “suggest improvements” — but challenge the core argument: Is this article saying anything new? Where does it become generic? What is the one sentence the reader should remember?
The translation stage needs explicit QA: check for remaining English text, flag literal-sounding sentences, verify that every paragraph has a cultural equivalent, not just a dictionary equivalent.
And the proofreading stage needs to be more aggressive: detect leftover source-language text, checks formatting consistency: headings, lists, markdown, metadata, links, image captions, flags inconsistent terminology across English and Chinese versions.
A Strange Feeling
In less than four hours, I moved all my Medium articles into a blog site I own.
There is a very specific kind of work that dies because it is annoying, not because it is hard. Migrating content is one of those tasks. Setting up a personal blog can be one of those tasks. Cleaning files, creating pages, translating drafts, organizing folders — all small enough to be boring but large enough to stop momentum.
The agent removed enough friction for the project to happen. That matters.
That is the part of AI agents I find most meaningful right now. Not that they make everything perfect. They don’t. Not that they remove the human. They shouldn’t. But they change the activation energy of a project.
They make it easier to begin. They make the first version appear faster. They turn vague intention into something visible.
And once something is visible, I can react to it. I can edit it. I can improve it. I can decide.
The agent did the boring work. I did the judgment work. And for this kind of project, that was enough to make the whole thing real.