Meet Gemini Diffusion: Google’s Bold New Approach to AI Writing
 Image generated by Google Gemini 2.5 Flash
Image generated by Google Gemini 2.5 Flash
Google just unveiled something fascinating at Google I/O 2025 on May 20th — Gemini Diffusion, an experimental research model that could completely transform how AI creates written content[1][2]. Let’s dive into what makes this approach so different and why it might matter for the future of how we interact with AI.
What Are Diffusion Models?
If you’ve been following AI image generation trends, you’ve likely already encountered diffusion models without realizing it[3]. These models work completely differently from traditional text generators, using a fascinating process:
- Start with noise: Instead of building text piece by piece, diffusion models actually begin with random noise and gradually refine it into something meaningful.
- Iterative refinement: Think of it like a sculptor gradually revealing a shape hidden in a block of marble. Through multiple steps, the model removes the noise until coherent content emerges.
- Parallel generation: Unlike traditional models that create one word (or token) at a time, diffusion models can generate entire blocks of content simultaneously — imagine writing multiple parts of a paragraph at once!
This is the same approach behind those stunning AI-generated images and videos you’ve probably seen from Google’s Imagen and Veo models[4]. Now, they’re bringing this powerful technique to text.
How Gemini Diffusion Works
If you’ve ever used ChatGPT, Claude, or previous Gemini models, you’ve experienced the traditional way AI generates text. These models (called autoregressive LLMs) create content one word at a time, with each new word depending on all the previous ones. It’s like writing a sentence from left to right, never looking ahead.
This approach works well but has some obvious limitations in speed and sometimes quality[5]. If you ever noticed how AI text sometimes feels like it’s forgetting what it was saying earlier in a response, that’s partly due to this word-by-word generation process.
Gemini Diffusion takes a completely different approach. According to Google DeepMind, it “learns to generate outputs by refining noise, step-by-step.” This means it can “error correct during the generation process,” potentially creating more coherent and consistent text[5].
Currently, Gemini Diffusion is still an experimental research model, not a finished product. Google is sharing it with “trusted testers” to gather feedback and improve the technology before making it more widely available[5]. Think of it as a glimpse into a possible future for AI text generation.
The Advantages of Diffusion for Text
Google highlights several compelling advantages of this new model:
- Lightning speed: This is perhaps the most striking benefit. Gemini Diffusion generates content at an astonishing 1,479 tokens per second, with just 0.84 seconds of overhead[5]. To put that in perspective, this is nearly 6 times faster than Google’s previous speedster, Gemini 2.0 Flash (which produces around 250 tokens per second)[5].
- More coherent responses: Because it can generate entire blocks of text simultaneously rather than word-by-word, the model potentially creates more coherent, consistent responses[5]. If you ever received an AI response that seemed to lose track of itself midway through, Diffusion models might help solve that problem.
- Self-correcting: The iterative refinement process allows the model to correct errors during generation[5]. It’s like having a built-in editor that reviews and improves the text before you ever see it.
- Efficiency: Early benchmarks show Gemini Diffusion achieves performance comparable to much larger models while being significantly faster[5]. This could mean more powerful AI capabilities without needing massive computational resources.
Potential Applications
Based on Google’s benchmark data, Gemini Diffusion shows particular promise in several exciting areas:
- Coding assistance: With impressive performance on coding benchmarks like HumanEval (89.6%) and MBPP (76.0%), this approach could transform how developers work with AI coding assistants. Imagine a programming helper that not only suggests code but can rapidly edit and refine entire functions at once.
- Math and science problem solving: The model shows potential for tackling complex mathematical reasoning tasks, scoring 23.3% on AIME 2025 and 40.4% on GPQA Diamond. This could help students, researchers, and professionals solve challenging problems more efficiently.
- Real-time conversational AI: With its exceptional speed (1,479 tokens per second), the model could power truly responsive AI assistants that feel more like talking to a human and less like waiting for a computer to think.
- Editing and refinement tools: Google specifically notes that diffusion models “excel at tasks like editing”[5]. This suggests exciting possibilities for writing assistants that can help you revise and polish your work with unprecedented speed and quality.
Benchmark Performance
The official benchmark results from Google DeepMind show the following comparison[5]:
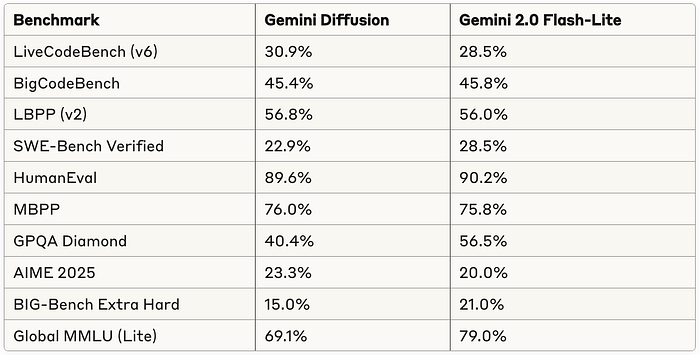
This table compares its performance to Gemini 2.0 Flash-Lite across key benchmarks. Standouts include coding tasks (LiveCodeBench 30.9%, MBPP: 76.0%), mathematical reasoning (AIME 2025: 23.3%).
Hybrid Approaches
What’s particularly fascinating about these benchmark results is seeing both what diffusion models do well and where they still face challenges. While Gemini Diffusion is blazingly fast and excels at certain structured tasks, researchers aren’t simply choosing between diffusion and traditional approaches — they’re exploring ways to combine them.