Attention is All You Need: The Simple Idea Behind Today’s AI Revolution

Back in 2017, a research paper dropped with the catchy title “Attention is All You Need”— and boy, did it live up to the hype. It went from zero to hero faster than your favorite binge-worthy show. One week nobody had heard of it, and the next? Everyone in tech couldn’t stop talking about these things called “transformers” (no, not the cool robots — though what they actually do is arguably cooler).
The title wasn’t just catchy marketing — it came from one of the authors, Jakob Uszkoreit, who suspected that attention mechanisms alone could handle language translation without the complex recurrence methods everyone was using.
The Problem: Sequential Thinking
Before this game-changer came along, AI trying to understand language was like that friend who can’t follow a story without constantly asking “Wait, what happened again?” These old systems (called recurrent neural networks) had to process words one at a time, making them painfully slow and forgetful with longer text.
The Solution: Parallel Processing
The researchers behind the paper had a wild idea: what if AI could look at an entire sentence all at once and figure out which words matter most for understanding other words? This “attention” mechanism works a lot like how you’re reading this right now.
Think about it — when you read “The cat sat on the mat because it was comfortable,” you instantly know “it” refers to “the mat” not “the cat.” You naturally pay attention to relationships between words, not just their order.
How Attention Actually Works
The transformative power of the attention mechanism lies in how it processes language in a completely different way than previous models. Let’s walk through it step by step, from intuition to implementation:
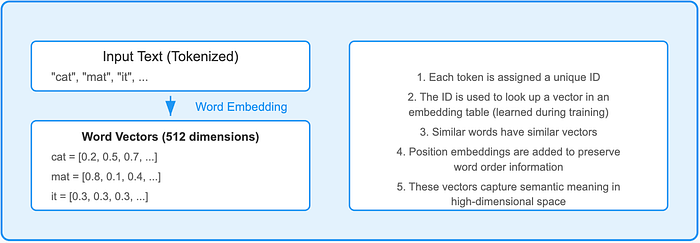
Step 1: From Words to Data Points
Each word in your sentence gets transformed into a multi-dimensional vector through embedding layers. These dense vectors capture semantic meaning in high-dimensional space.
Intuitively, this is like each word sending out signals about itself in hundreds of different dimensions. The word “cat” might become a 512-dimensional vector that encodes not just “cat-ness” but also information about being an animal, a pet, a noun, and so on.
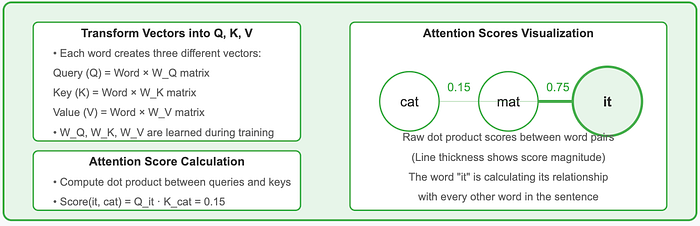
Step 2: Creating a Web of Connections
Once words are represented as vectors, they start “talking” to each other. The model computes compatibility scores between all possible word pairs using mathematical operations (specifically dot products of their “query” and “key” representations).
In our example “The cat sat on the mat because it was comfortable,” when processing “it,” the model calculates how relevant each previous word is. This creates direct connections between each pair of words, regardless of how far apart they are in the sentence.
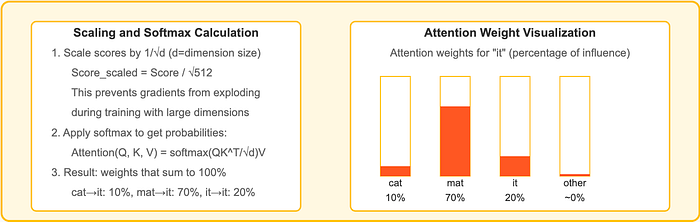
Step 3: Weighing What Matters
Not all connections are equally important. The raw scores get scaled (typically divided by the square root of the dimension size) to stabilize gradients during training. Then a “softmax” function converts these scores into percentages that add up to 100%.
This is where the magic happens — rather than just looking at nearby words, the model might assign a 70% attention weight to “mat” but only 10% to “cat” when processing “it,” correctly figuring out the reference.
Step 4: Building Context-Aware Meaning
Finally, each word’s representation gets updated based on these attention weights. The model creates a new vector for each word by calculating a weighted sum — combining information from all other words according to their attention scores. In our example, “it” would get 70% of its new meaning from “mat,” 10% from “cat,” and the rest from other words, effectively resolving that “it” refers to the mat being comfortable.

What makes this revolutionary is that all these connections happen in parallel rather than sequentially. The Transformer can process all words simultaneously, making it vastly more efficient while capturing relationships between words regardless of distance. Different “attention heads” specialize in different types of relationships, giving the model a rich understanding of language that previous architectures couldn’t achieve.
The Impact: Revolutionary Results
The Transformer architecture didn’t just incrementally improve AI systems — it fundamentally changed what was possible. Here’s why it was such a breakthrough:
- Speed Revolution: By processing text in parallel rather than sequentially, Transformers dramatically accelerated both training and inference times. Tasks that previously took weeks could now be completed in days.
- Scaling Potential: The architecture could efficiently handle longer texts and larger datasets, opening the door to training on massive text collections from across the internet.
- Quality Leap: Translation quality, comprehension, and generation all showed substantial improvements over previous approaches, proving that attention-based models could understand language context better than their predecessors.
- Resource Efficiency: Despite their power, Transformers made more efficient use of computing resources, allowing researchers and companies with less access to specialized hardware to participate in AI advancement.
These improvements weren’t just academic — they set the stage for the explosive growth in language AI that followed, from BERT to GPT and beyond. The Transformer architecture became the foundation upon which most modern language models are built.
The Team: Minds Behind the Magic
The paper came from a team of eight Google researchers called “Team Transformer” (yes, really!). The name “Transformer” wasn’t even technical — Jakob Uszkoreit, one of the key authors, just liked how it sounded.
After publishing, most of the team left Google to pursue their own AI ventures. Their paper has since been cited over 173,000 times, becoming one of the most influential research works of this century.
The Legacy: Why It Matters
This explains why modern AI suddenly seems so much smarter than what we had just a few years ago. The breakthrough was getting AI to focus on relationships rather than just processing words in order.
Funny enough, all this progress started with researchers basically telling AI to “pay attention” — the same thing parents and teachers have been saying forever. Turns out that advice works just as well for artificial intelligence as it does for distracted kids!
Now if only we could get AI to clean its room and finish its homework, we’d really be onto something…